고정 헤더 영역
상세 컨텐츠
본문
Abstract
- Internal Covariate Shift는 훈련을 저하시키는 주된 원인이다.
- internal covariate shift : 이전층의 파라미터 분포 변화에 따라 각 층의 input 분포가 달라지면서 네트워크 훈련이 복잡해지는 현상
- lower learning rate, careful parameter initialize 등이 요구됨
- 하지만, 이는 normalizing layer inputs를 통해 해결할 수 있음
- 이를 해결할 두 가지 방법
- normalization을 모델의 아키테처에 포함시킨다.
- 각 mini-batch 별로 normalization을 수행한다.
- Batch Normalization의 장점
- higher learning rate
- less careful about initialization
- act as regularizer
- eliminate Dropout
- Batch Normalization의 효과
- 기존 모델보다 14배 적은 training steps으로 same accuracy 달성
- 앙상블 기법을 적용할 경우, 4.9% 의 error(top5 수준) 및 인간 판별기의 정확성 초과
1. Introduction
- mini-batches를 사용하는 것의 장점
- mini-batch의 손실함수 gradient는 전체 training set의 gradient 추정치이며, 이는 batch size가 커질수록 정확해진다.
- batch를 계산하는 것이 m개의 개별 예시들을 계산하는 것보다 효율적이다.
- SGD는 단순하고 효과적이지만, 모델 parameter에 careful tuning이 필요함
- the inputs to each layer are affected by the parameters of all preceding layers
- small changes to network parameters amplify as the network becomes deeper
- layers의 input distribution의 변화는 layers가 지속적으로 새로운 distribution에 적응해야하기 때문에 문제가 생긴다.
- covariate shift : learning system의 input distribution이 변화하는 것
- covariate shift는 learning system 전체로 확장될 수 있다.
- 이전층의 출력값이 sub-networks나 다음 층의 input으로 사용되기 때문
- 따라서 layer input을 같게 한들면 훨씬 효율적으로 학습시킬 수 있다.
- ex. training & test data의 distribution을 같게 한다던지
- 이렇게 해줌으로써, 다음 층의 파라미터는 분포 변화를 보정하기 위해 재조정할 필요가 없어진다.

Internal Covariate extends to other layers
- 분포를 고정시키는 것은 sub-networks의 outside에도 긍정적인 결과를 야기함
- 시그모이드 함수를 예를 들어 생각해보면,
- z = g(Wu + b), g(x) = (1 + exp(-x))**-1
- 시그모이드 함수의 인수는 Wu + b이며, 학습이 진행되면서 W, b 값에 따라 기울기나 결과값이 결정됨
- propagation을 진행하며 하위 층들을 통과할 때 분포가 다르다면 이 값은 양 극단으로 치우칠 확률이 높아짐
- 이는 네트워크의 depth가 깊어질수록 증폭됨
- 아래와 같은 방법으로 해결할 수 있음
- ReLu 사용
- careful initializing
- small learning rate
- 하지만, 네트워크가 훈련되는 동안 분포를 stable하는 것은 다음을 보증한다.
- optimizer는 포화 상태에 덜 빠지게 될 것
- 훈련이 가속화될 것
- 시그모이드 함수를 예를 들어 생각해보면,
- Batch Normalization
- layer inputs의 means & variance를 normalization 시킴으로 internal covariate shift 제거 및 극적으로 훈련 속도를 가속효과를 얻는다.
- gradient parameter의 scale과 initial value의 읜존성을 줄이고 higher learning rate와 수렴 위험성을 벗어나도록 한다.
2. Towards Reducing Internal Covariate Shift
- inputs 가 whitened 되었을 때 네트워크 학습 수렴 속도가 훨씬 빠르다고 알려져있다.
- whitened : lineary transformed to have zero means and unit variances, and decorrelated
- 각 layes를 whitening해줌으로써, 고정된 distribution을 달성하고, internal coraviate shift의 부정적인 효과들을 제거할 수 있을 것이다.
- 하지만 이는 gradient step이 변화는 효과보다 normalization update에 더 영향을 받는 모습을 보인다.whitening은 모든 training step or some interval, network의 직접 수정 or 파라미터의 간접 수정 등의 방식으로 이루어진다.

whitening ignores the dependence of E(x) on b
- 위 수식의 결론을 보면, b에 대한 업데이트와 손실에 대한 업데이트는 변화가 없어진다.
- 결국 gradient descent optimization이 normalization을 반영하지 못하는 문제가 발생하고, 이를 해결하기 위해서는 모든 파라미터 값이 항상 desired distribution을 갖도록 해야한다.




whitening back progation
- 또한 위 수식을 통해 whitening의 propagation 과정을 관찰할 수 있는데 이 framewordk 내부에서 확인할 수 있는 점은 이 과정의 cost가 너무 비싸다는 것이다.
3. Normalization via Mini-Batch Statistics
각 layer을 전부 whitening하는 것은 비용이 많이 들고 모든 곳이 미분가능하지 않기 때문에 다른 방법을 사용할 수 있다.
평균0, 분산 1을 가지게 함으로써 각 scalar feature을 독립적으로 정규화하여 convergence를 빠르게 하고 feature들을 decorrelated한다.

3.1 Training and Inference with Batch-Normalized Networks
x를 입력값으로 받은 layer에 이제 BN(x)를 받게 한다. training과정에선 데이터가 batch단위로 들어오기 때문에 배치단위의 평균과 분산을 계산하여 정규화를 수행하지만 inference과정에선 미니배치단위가 아닌 population을 이용해 배치단위의 고정된 평균과 분산을 이용하여 정규화를 수행한다. mini-batch 단위를 사용한다면 학습데이터로부터 얻은 데이터의 특성을 적절히 활용할 수 없기 때문에 학습데이터를 대표할 수 있는 값을 사용한다.
moving average(이동평균)을 사용해 미니배치의 분산들로 전체 분산을 추정하고 inference과정에서 평균과 분산이 고정돼있어서 훈련되는 동안 모델정확도를 tracking할 수 있다. test과정에서 표본 분산의 평균값에 m/(m-1)을 곱하여 모분산으로 향하지 않는 unbiased variance estimate를 사용한다.

3.2 Batch-Normalized Convolutional Networks
3.3 Batch Normalization enables higher learning rates
너무 높은 learning rate는 local minima에 빠지거나 기울기폭주/사라짐을 야기할 수 있는데, 이를 batch normalization으로 해결할 수 있다.
- network전반의 activation을 정규화함으로써, 파라미터의 작은 변화를 더 크고 차선인 변화로 확대되는 것을 막는다.
- parameter scale에 backpropagation이 영향을 받지 않고 larger weights가 더 작은 기울기를 갖게 하며 parameter growth를 안정화하고 더 유동성있는(resilient) 훈련이 가능하게 한다

scale a가 Jacobian layer에 영향을 미치지 않고 결과적으로 gradient propagation에도 영향을 미치지 않게 된다.
- batch 정규화가 layer Jacobian을 훈련에 유용한, 1에 가까운 단일값을 가지게한다는 추측을 했지만 transformation이 linear이 아니며 정규화된 값이 Gaussian이거나 독립적이라는 것을 보장할 수 없어 이 점에 대해선 추후 연구에서 다룬다고 한다.
3.4 Batch Normalization regularizes the model
Network generlization -> batch normalization으로 훈련하는 경우, 훈련샘플은 미니배치의 다른 샘플들과 결합되고 훈련 network는 주어진 훈련샘플을 위한 결정값(deterministic value)를 더이상 만들어내지 않는다.
4. Experiments
4.1 Activations over time
28*28 이진이미지를 입력값으로, 각 100개의 activation을 포함한 3개의 FClayer을 포함한 network로 각 은닉층은 sigmoid nonlinearity로 계산하며 W는 랜덤 가우시안 값으로 초기화하여 MNIST dataset을 이용한 batch normalization 실험을 진행한다. MNIST에 뛰어난 성능을 얻어내려는 목적보다는 baseline과 batch 정규화된 network사이의 비교에 초점을 맞춘다.
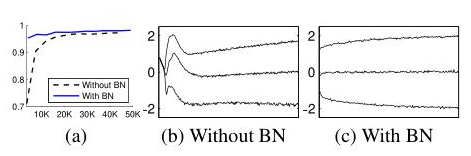
배치정규화된 네트워크는 높은 test accuracy를 보이고, original network는 이후의 layer의 훈련을 복잡케 하는 평균, 분산 모두에서 확연한 변화를 보이지만 배치정규화된 네트워크는 높은 test accuracy를 보이며 훈련이 진행됨에 따라 분포가 훨씬 더 안정적인 것을 볼 수 있다.
4.2 ImageNet classification
momentum을 이용한 SGD를 사용하고 ImageNet 분류로 훈련된 inception network의 변형에 배치 정규화를 적용
- 해당 논문에서 이 모델을 Inception이라고 칭한다.
4.2.1 Accelerating BN Networks
단순히 배치정규화를 network에 추가하는 것이 아니라 network와 훈련파라미터에 변화를 줌으로써 배치정규화의 이점을 더 잘 활용할 수 있다.
- learning rate를 높인다
- Dropout를 제거한다 -> overfitting을 증가시키지 않으면서도 modified BN-Inception으로부터 dropout를 제거함으로써 훈련속도를 높인다.
- L2 가중치정규화를 감소시킨다 -> Inception의 경우 L2 loss가 오버피팅을 막지만 BN-Inception의 경우 이 loss의 가중치는 5의 배수만큼씩 줄어들어 검증데이터를 나누는 과정에 정확도를 높인다.
- learning rate decay(학습이 진행됨에 따라 learning rate를 점차 줄이는 것)를 가속화한다 -> Inception보다 6배 빠르게 learning rate를 낮춘다
- local response normalization을 제거한다 -> Inception이나 다른 networks의 경우에는 local response normalization을 필요로 하지만 batch normalization은 필수적이지 않다
- training examples를 철저히 셔플한다 -> mini-batch에서 동일한 샘플이 항상 나오는 것을 막는 셔플링을 통해 정확도 1%의 개선을 이룰 수 있다
- Photometric distortion(광도 왜곡)을 줄인다 -> batch normalization이 학습이 빨리됨에 따라 학습 샘플을 더 적게 관찰하게 되는데, 왜곡이 덜 이뤄지게 함으로써 trainer가 실제 이미지에 더 집중하게 한다.
4.2.2 Single-Network Classification


Batch normalization없는 Inception모델의 최대정확도는 72.2%로 Batch normalization을 사용한 다른 모델들은 이 정확도를 달성할 때 없는 모델보다 훨씬 적은 수의 step만을 거쳐 달성할 수 있다. BN-x5-Sigmoid는 69.8%의 정확도를 가지지만 batch normalization이 없다면 이보다 나은 정확도를 내지 못한다.
4.2.3 Ensemble Classification
5. Conclusion
deep networks의 훈련을 가속화하고, 훈련을 복잡하게 하는 covariate shift를 제거함으로써 훈련에 도움을 주기 위해 batch normalization은 제시되었다. 근본적인 원인으로 covairate shift를 꼬집으며 적절한 normalization과 scale/shift를 이를 위한 해결방안으로 제시한다. 정규화가 네트워크를 훈련하기 전에 적절한 최적화 방법으로 다뤄지는 것을 보장하며 통계적 최적화 방법을 사용가능하게 하여 각 미니배치마다 정규화를 수행하고 정규화 파라미터를 통해 경사를 backpropagate할 수 있게 되었다.
batch normalization을 통해 learning rate를 높이고 dropout을 제거하며 작은 training step으로 이전의 기법들의 정확도를 따라잡을 수 있게 되었다.
또한 이를 통해 훈련동안 activation value의 안정적인 분포를 이루어 비선형성이전에 이를 적용해 더 안정적인 분포를 만들고자 한다.
'2023 Summer Session > DL' 카테고리의 다른 글
| [4주차/DL2팀/논문 리뷰] (0) | 2023.08.08 |
|---|---|
| [4주차 / DL 1팀 / 논문 리뷰 ] Deep Residual Learning for Image Recognition (0) | 2023.08.03 |
| [3주차/DL2팀/논문 리뷰] Layer Normalization (0) | 2023.07.26 |
| [2주차/DL 2팀/논문 리뷰] ADAM: A METHOD FOR STOCHASTIC OPTIMIZATION (0) | 2023.07.20 |
| [2주차 / DL 1팀 / 논문 리뷰] Neural Networks for Machine Learning (0) | 2023.07.20 |





댓글 영역