고정 헤더 영역
상세 컨텐츠
본문 제목
[6주차/최유민/논문리뷰] High-Resolution Image Synthesis with Latent Diffusion Models
본문
1. Abstract
- Diffusion model은 이미 image synthesis 에서 SOTA를 달성하였음
- 하지만, 기존 모델들은 픽셀 공간에서 연산을 진행하여, 수백일의 GPUdays가 필요하고, inference 비용이 높음
- 본 논문에선 pretrained AutoEncoder를 이용, latent space에서 DM training을 적용해 적은 computional resourse로 좋은 퀄리티를 얻어냄
- 복잡성 감소와 디테일 보존 사이에서 최적 지점 도달
- Attention layer를 추가하여 다양한 task에 diffusion model을 적용하였음
- SOTA : image inpainting, class-conditional image synthesis
- Competitive performance : text-to-image synthesis, unconditional image generation, super-resolution
2. Introduction
Departure to Latent Space
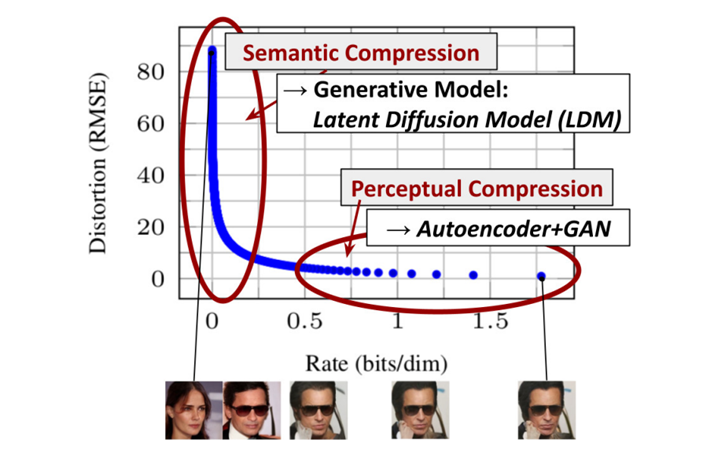

- 왜 Pixel Space에서 denoising 을 진행해야 할까?
- 더 작은 공간에서 Denosing을 진행하고, 이미지 디테일을 위한 모델을 추가하면 어떨까?
이 아이디어에서 모델이 출발한다.
아래 DDPM 논문에서 가져온 figure7에서 왼쪽에서 4번째 사진을 보면, 오른쪽 아래 noise를 공유하는 3개의 사진이 큰육안으로 큰 차이가 느껴지지 않는 것을 볼 수 있다.
즉, pixel space에서 denoising을 진행하는 것이 효율적이지 않다는 것을 의미한다.
3. Method
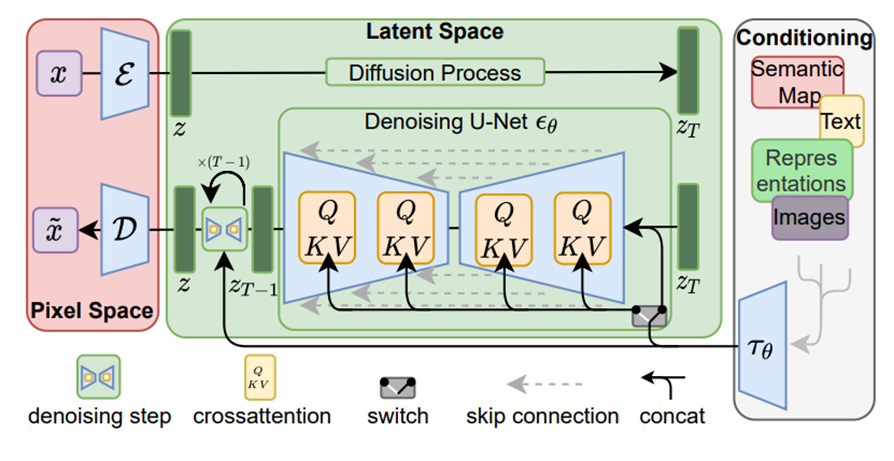
latent diffusion model에서는 Perceptual / Semantic을 학습을 명확히 분리한다.
Pixel Space에서는 AutoEncoder를 사용하고, latent space에서는 기존의 Diffusion model을 사용한다.
이 방법으로 고차원 이미지 정보는 남겨두면서 DM이 효율적인 연산이 가능하게 한다.
Perceptual Image Compression
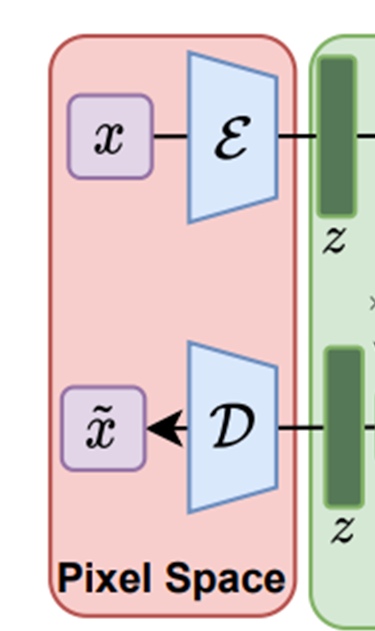
Pixel Space에서의 모델은 Autoencoder + patch-based adversarial objective를 이용해서 학습된다.
여기서 모델이 이미지를 얼마나 압축시킬 것인지를 정하는 Downsampling factor를 이용한다.
Downsampling factor는 f =H/h=W/w 로 정의되며 f=2^m 을 사용한다.

기존 AutoEncoder 모델의 구조이다. 이미지 x를 latent vector z로 압축할 수 있는 Encoder를 학습하는 것을 목표로 한다.

AutoEncoder 학습에선 Normal autoencoder 학습 방법이 아닌 VQGAN에서의 방식을 사용한다.

인코더, 디코더 부분을 generator으로, 생성된 이미지를 fake image로 두고 GAN학습에 사용되는 방식으로 학습을 진행한다고 볼 수 있다.
L_rec=MSE(x, D(ε(x)) : reconstruction loss - autoencoder를 통과한 이미지가 기존 이미지와 차이가 적어야 한다.
L_reg : regulization loss - latent vector 가 N(0,1)을 따르도록 정규화 : KL (ε(x), N(0,1)) OR codebook |Z| 로 정규화
본 논문에선 정규화 방법으로 위 두 가지 방법을 제시하고 있다.
아래 두 Loss term 은 GAN 모델에서 등장하는 loss term 이다.
L_adv=D_φ (D(ε(x)))
log (D_φ (x)) : discriminator
Latent Diffusion Models
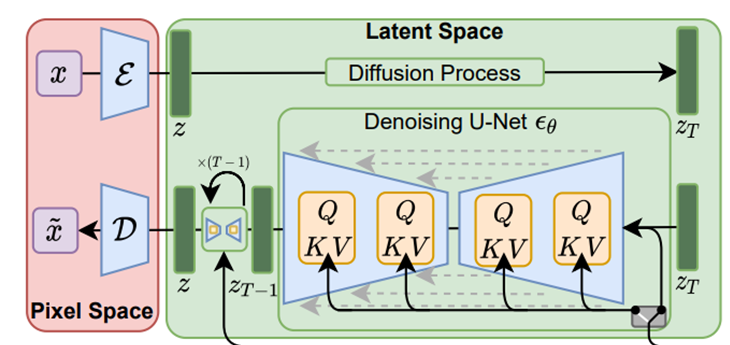
-기존 Diffusion model의 Loss
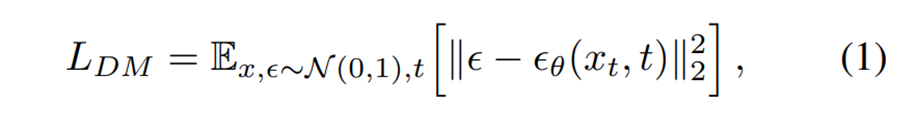
-LDM Loss

pixel space가 아닌 latent space에서 denoising 을 진행한다.
Conditioning Mechanisms
다음은 본 논문에서 diffusion 모델을 어떻게 다른 여러 task에 적용할 수 있었는지 알아보자.
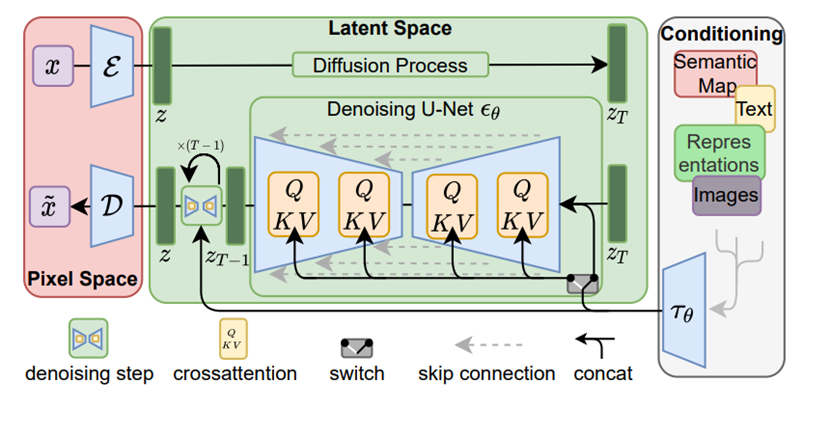
Text, Semantic map, images 등등 여러 종류의 컨디셔닝이 가능하다.
Cross attention Or concatenation 방식 - 어떤 modality가 들어오냐에 따라 달라진다.
Text의 경우 attention을 적용하고, semantic map의 경우 concatenation 방식을 적용한다.
Text prompt 가 입력되는 경우, DM의 backbone 모델인 Unet architecture 안에 레이어에 cross attention을 적용한다.
이미지 각 patch가 Q (query)로 사용되고, 임베딩 된 텍스트가 Key, value로 사용되어 크로스 어텐션이 진행된다.
텍스트와 이미지 사이의 information binding이 진행되고, 텍스트가 반영된 이미지가 생성되게 된다.
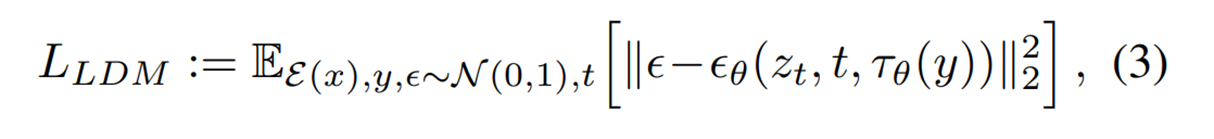
컨디셔닝 된 LDM의 loss는 타우_theta(y)가 추가된 것을 볼 수 있다.
텍스트 프롬프트가 컨디셔닝 된 경우
Google의 BERT-tokenizer사용하며 τ_θ 는 Unet layer 에 들어갈 latent code를 반환하는 transformer 모델이 된다.

아래 3가지 Task에 대해선 Concatenating information to input of Denosing U-Net을 진행한다.

4. Experiment
On Perceptual Compression Tradeoffs
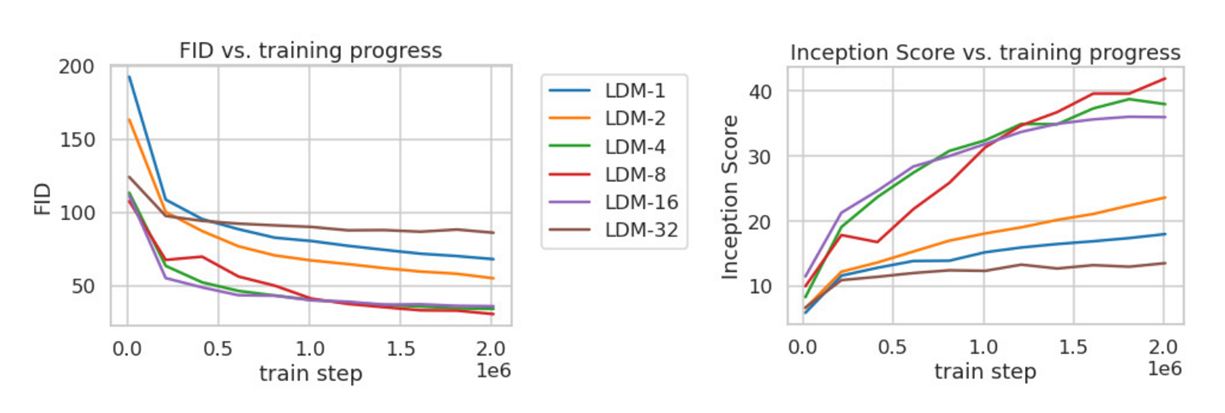
Downsampling factor f ∈ {1, 2, 4, 8, 16, 32} 에서 어떤 trade off가 발생하는지 알아보자
f = 1 일 때는 기존 pixel-based DM과 동일하다.
너무 작은 f의 경우(LDM-1, LDM-2) 학습을 느리게 한다.
너무 큰 f의 경우(LDM-32) 일정 step 이후 학습이 정체된다.
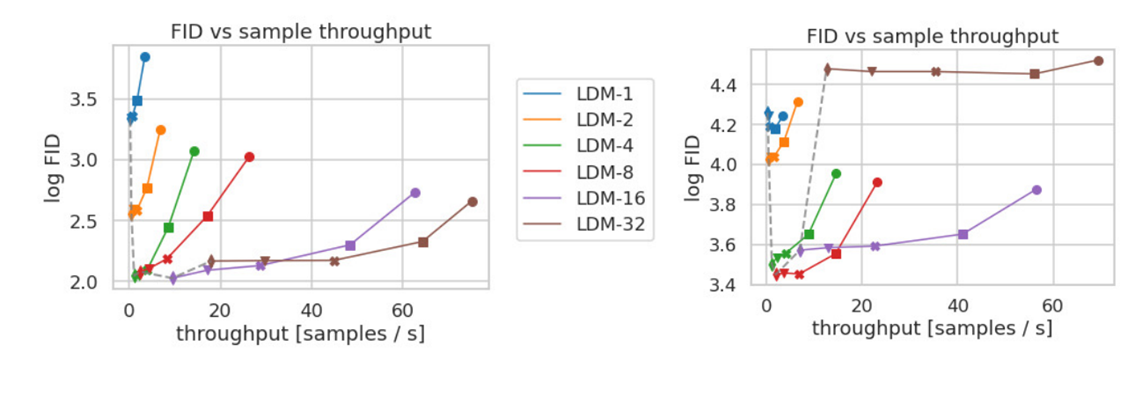
CelebA-HQ(좌)와 ImageNet(우)으로 학습한 LDM의 샘플링 속도와 FID를 비교한 결과이다.
각 마커는 DDIM sampler를 적용한 10, 20, 50, 100, 200 denoising step을 나타낸다. (점선 : 200step에서의 모델)
LDM-4, LDM-8 모델의 성능이 가장 좋은 것을 볼 수 있다.
LDM-1에 비해, 낮은 FID score와 더 높은 sampling speed 를 가진 것을 확인할 수 있다.
5. Limitation & Social Impact
Limitation

Computational requierments를 획기적으로 줄인 건 맞지만, 이미지 생성 과정이 여전히 GAN에 비교하면 느리다.
높은 정확도가 요구되는 task에서 LDM의 사용이 괜찮은지는 아직 의문이 든다.
Downsampling factor f = 4를 사용하여 이미지 퀄리티 loss가 적긴 하지만, pixel space에서 정확도를 요구하는 task에선 bottleneck의 우려가 있다. (superresolution models에서 바퀴살 구현이 정확하지 않은 것을 볼 수 있다.)
Social Impact
생성 모델은 양날의 검이다.
생성 모델은 창의적인 응용이 가능하다.모델 학습 과정에 컴퓨터 리소스가 적게 들어가게 되면서 기술 접근성이 높아진다.
반면, 생성이 쉬워지게 되면서 조작된 정보가 퍼지기 쉽고, 딥페이크 등의 문제가 생긴다.
생성 모델에 사용되는 학습 데이터가 공개되면서, 개인 정보의 문제도 생긴다.
Deep learning modules는 데이터셋에 존재하는 bias를 반영하거나 더 심하게 만드는 경향이 있다.
Diffusion model의 경우 GAN 기반 모델보다 데이터 분포의 범위를 더 잘 커버하긴 하지만 LDM에서 사용되는 접근법도 얼마나 데이터를 잘못 표현하는지는 중요한 연구 주제이다.
6. 참고자료
Rombach, Robin, et al. “High-Resolution Image Synthesis with Latent Diffusion Models”, IEEE, 2022
Ho, Jonathan, Ajay Jain, and Pieter Abbeel. "Denoising diffusion probabilistic models." Advances in Neural Information Processing Systems 33, 2020
Patrick Esser, Robin Rombach, and Bjorn Ommer. “Taming transformers for high-resolution image synthesis” CoRR, 2020
Gabriel Mongaras, “Stable/Latent Diffusion - High-Resolution Image Synthesis with Latent Diffusion Models Explained” , https://www.youtube.com/watch?v=rC34475rEnw&t=236s





댓글 영역