고정 헤더 영역
상세 컨텐츠
본문 제목
[6주차 / 임종우 / 논문리뷰] ViTPose : Simple Vision Transformer Baselines for Human Pose Estimation
본문
Abstract
- Plain Vit를 사용하여 pose estimation을 수행하려 함
- ViT의 모델 구조의 간단함, 모델 사이즈의 확장성, 학습의 유연함, 모델 사이 지식의 전파 가능성이라는 장점을 활용하여 ViTPose의 모델 구조를 제시함
- attention type, input resolution, pre training and finetuning strategy등에 대해 매우 유연한 특징
- knwoledge token을 사용하여 large model의 학습을 small model로 쉽게 transfer 할 수 있음
- MS COCO keypotint detection에서 SOTA를 달성함
등장 배경 및 기본 구조
- 기존 VIT기반 pose estimation은 feature extraction을 위해 CNN을 필요로 했거나, task에 맞춤화된 복잡한 transformer 구조를 필요로 하였다.
- 따라서 plain vision transformer를 사용하여 pose estimation을 잘 수행하고자 하는 방법에 대한 연구가 진행되었다.
- 이를 위해 고안된 ViTPose는 plain, non-hierarchical vision transformer를 backbone으로 하여 feature map을 추출하고, masked image modeling pretext task를 통해 해당 backbone을 학습시킨다.
- 그 후 2개의 deconv layer와 하나의 prediction layer로 구성된 lightweight decoder로 feature map을 upsampling하고 keypoint에 대한 heatmap을 regress한다.
- detector로 사람을 찾은 후, ViTPose를 사용하여 keypoints를 추정하는 top-down 형
- 새로운 특별한 알고리즘을 사용하지 않고도 단지 간단한 transformer만을 사용한 baseline model로 pose estimation에서 sota를 기록하였다는 의미가 존재한다.

특징
- ViT의 성능은 Simplicity, scalbility, flexibility, transferability의 특성에서 기인한다.
- Simplicity : ViT의 feature representation 성능이 아주 좋기 때문에, ViTPose 모델은 매우 간단한 구조를 가지고 있다.
- 예를 들어, backbone encoder를 설계하기 위해 특정 도메인의 지식이 필요하지 않고, 단지 여러 개의 plain non-hierarchical transformer를 쌓아서 사용하였다.
- 디코더의 경우 simple함을 위해 skip connection이나 cross attention과 같은 기술을 사용하지 않고 단순히 2개의 deconv 및 1개의 prediction(conv 1x1) layer로 구성하였다. (classic decoder)
- 심지어 더 간단하게 구성할 수도 있다. (simple decoder) feature map을 단순한 bilinear interpolation으로 4배 upsampling하고, 3x3 conv를 사용해 heatmap을 얻어낸다.
- simple decoder의 경우 non-linearity가 좀 떨어지지만, 그럼에도 불구하고 classic decoder와 큰 성능차이가 나지 않았다.
- 이러한 구조적 간단함으로 인해 더 나은 병렬처리, inference 속도 및 성능을 가진다.
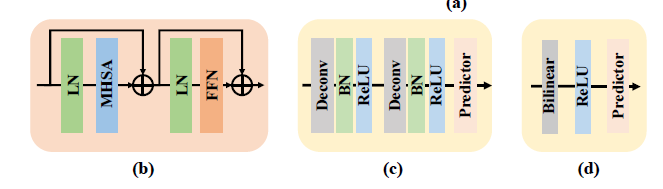
Scalability : scalable한 simple pre-trained vision transformer의 발전으로, layer의 수, feature dimenstion의 수를 조절하여 모델의 사이즈를 쉽게 조절할 수 있다.
- ViT-B, L, H, ViTAE-G등 다양한 모델을 디코더로 사용

Flexibility : 아주 유연한 학습을 적용할 수 있다. 모델을 조금만 수정하면 다양한 input resolution과 feture resolution을 이용하여 학습할 수 있고, 여러개의 pose dataset에 대해서도 추가적인 decoder를 사용함으로써 유연하게 적용할 수 있다.
- pre-training data flexibility : MAE(masking)을 사용하여 pre-training에 있어 부족한 데이터의 양을 해결하고 flexibililty를 제공함
- reolution flexibility : down sampling ratio d와 input size를 조절하여 inpiut/feature resolution을 조절할 수 있다.
- attention type flexibility : full attention은 메모리 사용량이 너무 많기 때문에 window-based attention을 사용한다. 이때 global context를 위하여 Shift window 혹은 Pooling window 방식을 사용한다.
- finetuning flexibility : 여러 모듈에 대해 frozen 혹은 unfrozen으로 설정해가며 fine tuning을 진행한다.
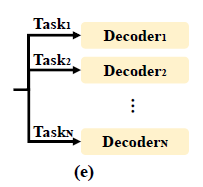
- task flexibility : decoder가 간단하기 때문에, 많은 추가비용 없이 여러개의 decoder를 사용해 multiple pose estimation을 진행할 수 있다.
- Trasferability : large ViTPose의 지식을 small model로 transfer시켜 우수한 성능을 낼 수 있다. 이를 위해 knowledge token을 사용한다.
- knowledge distillation : Teacher network와 student network에 대해 output distillation loss(Teacher와 student의 output loss)를 추가하는 간단한 방법 등을 사용할 수 있다.
- ViTPose에서는 그러한 방법이 아닌, token-based distillation method를 사용한다. 학습 가능한 knowledge token 을 임의의 값으로 초기화한 후, patch embedding에 추가하는 것이다. 그 후 Teache model은 freeze 하고, knowledge token만 tuning을 진행한다.
- 결과 token으로는 input에 대한 teacher network의 prediction과 ground truth 사이의 loss를 최소화시키는 값을 사용한다. 이 token이 student network의 patch embedding에 포함되어 사용됨으로써 knowledge transfer가 가능하다.
결과
- ViTAE-G를 backbone으로 사용한 모델이 SOTA를 기록하였다.
- 더 복잡한 decoder 혹은 FPN을 사용한다면 어떨지에 대한 연구가 필요하다는 한계가 존재한다.
- VitPose는 vision transformer기반 human pose estimation에 사용될 수 있는 간단한 모델로써, simplicity, scalability, flexibility, transferability를 특징으로 가져 좋은 성능을 낸다.





댓글 영역