고정 헤더 영역
상세 컨텐츠
본문
Generative Adversarial Nets
Abstract
- adversarial process, Generator와 Discriminator의 적대적 학습을 통한 새로운 생성모델 제시
- Generator로 하여금 Discriminator가 최대한 틀린 판단을 하도록 이미지를 생성해야하는 two-player game 형태의 학습 과정 제시
- G와 D 모두 neural network(fc layers)로 이루어져 있어 end-to-end 학습이 가능함
Introduction
이전까지, 딥러닝의 유망함을 널리 알려져왔고 무언가를 판별(discriminative)하는 분야에서 딥러닝이 많은 성공을 가져왔다.
반면, 무언가를 생성(generate)하는 분야에서 딥러닝은 그만큼의 임팩트를 남기지 못했다.
이는 maximium likelihood estimation이나 관련된 통계적 계산이 너무 복잡해 해결하기 어려웠고, 무언가를 생성해낼때 linear한 요소들이 가지는 장점을 활용하기 어려웠기 때문이다.
논문에서 제안하는 adversarial nets 프레임워크를 쉽게 생각해보자면, generative model은 걸리지 않고 위조지폐를 만드려는 팀으로, discriminative model은 위조지폐를 잡아내려는 경찰로 생각할 수 있다.
이러한 game에서의 경쟁은 양 팀에 모두 성능 향상을 불러와 결국 generative가 진짜를 만들어낼 때까지 계속될 것이다.
다양한 종류의 모델과 최적화 기법을 사용하는 수많은 adversarial 학습 방법 중, 본 논문에서는 MLP로 이루어진 discriminative 와 generative 모델을 사용한다. generative model은 랜덤 노이즈를 input으로 주어 샘플을 만들어내도록 한다.
이를 adeversarial nets라고 부를 것이다.
Markob chain이나 기타 다른 방법의 사용 없이 오직 MLP에서의 역전파와 dropout 만으로 학습을 진행할 것이다.
Related works
- Boltzmann machines
- undirect graphical models with latent variables
- 내부 동작에 계산이 어려운 경우가 많아 Markov chain Monte Carlo 방법을 통해 추정해야 함
- 이렇게 MCMC에 의존하는 모델의 경우 학습 과정에서 mixing에 의한 문제가 발생할 수 있다.
- Deep belief networks(DBN)
- hybrid models (single undirected and seberal directed layers)
- undirected와 directed model 모두를 고려해야하기 때문에 계산적 어려움 존재
- score-matching or Noise contrastive estimation(NCE)를 사용
- log-likelihood를 제한하거나 근사하지 않는 방법
- VAE
Adversarial nets
Generator
input : noise variables $p_z(z)$
learn : generator’s distribution $p_g$
a mapping to data space as $G(z;\theta_g)$
G : 파라미터 $\theta_g$를 가지는 MLP로 구성된 미분가능한 함수
즉, generator는 noise를 input으로 받아 특정한 분포 $p_g$를 학습한다.
Discriminator
$D(x;\theta_d)$, output : single scalar
represent the probability that x came from the data rather than $p_g$
즉, D는 input x가 실제 data에서 온 것인지, generator가 생성한 확률분포 $p_g$에서 온 것인지 판단한다.
train
D : 실제 example과 Generator에 의해 생성된 sample을 각각 최대한 잘 알아맞추도록 학습
G : $log(1-D(G(z)))$를 최소화하도록 학습
즉, 일종의 two-player minimax game을 진행하는 셈.
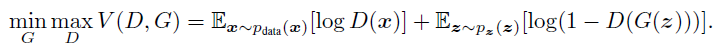

해당 Figure를 보면, D와 G를 어떻게 학습시키는지에 대한 내용을 알 수 있다.
disciriminative distribution이 파란색, 실제 data의 distribution이 검정색, generative distirbution이 초록색 line이다.
아래 있는 수평선은 uniformly sampling된 z들이, generative distribution에 의해 x에 어떻게 mapping 되는지를 보여준다. ($x = G(z)$)
(a)를 보면, 먼저 학습이 어느 정도 진행 되어 G와 D가 수렴에 가까워져 가고 있는 상황이다.
(b)에서 볼 수 있듯, iteration으로 이루어지는 학습 내부에서 먼저 D를 학습시켜 수렴에 가까워지도록 한다.
(c)에서는 그 후 G를 업데이트 하는 모습을 보여주고 있는데, D의 gradient가 G(z)를 실제 데이터로 판단될 수 있는 방향으로 이끈다.
(d)에선, 충분히 학습이 진행되어 $p_g = p_{data}$가 되어 더 이상 학습이 진행될 수 없이 수렴된 상황이다. 이 경우, discriminator는 진짜와 가짜를 구분할 수 없어 D(x) = 0.5가 된다.
다만 논문에서는, 한 iteration마다 D를 끝까지 학습시키는 것은 계산적으로도 어렵고 overfitting의 우려도 있기 때문에 D를 k step 학습시키고, G를 한번 학습시키는 방향으로 학습을 진행하였다고 설명하고 있다.
이렇게 학습을 진행한다면 G가 천천히 변화할때, G가 최적화된 해에 가깝게 유지될 수 있다.
실제 학습을 진행할때, 위에 등장한 수식은 G가 잘 학습될 정도의 충분한 gradient를 제공하지 못할 수 있다.
학습 초기에 G의 초기화가 잘 되어있지 않다면, D가 가짜와 진짜를 잘 판별할 것이고, $log(1-D(G(z)))$가 수렴하게 되기 때문이다.
따라서, G로 하여금 $log(1-D(G(z)))$를 최소화하도록 학습하는 것이 아닌, $log D(G(z))$를 최대화하도록 학습을 진행한다.
이렇게 objective function을 변경하여도 G와 D는 전과 같은 곳으로 수렴하되, 초기 학습에서 더 strong gradient로 학습이 잘 진행될 것이다.

- Algorhitm 1에서 표현하고 있듯이,
- 먼저 discriminator를 목적함수를 max시키는 방향으로 학습한 후
- generator를 목적함수를 minimize 시키는 방향으로 학습을 진행한다.
Theoretical Results
- 해당 부분에서는, $p_g = p_{data}$일때에만 모델이 우리가 원하는 학습 목표에 수렴하며, 실제 GAN의 학습 알고리즘이 이렇게 수렴 가능함을 증명하고 있다.
Global Optimality of $p_g = p_{data}$
최적의 discriminator D와 임의의 고정된 generator G에 대하여,

다음과 같이 증명할 수 있다.
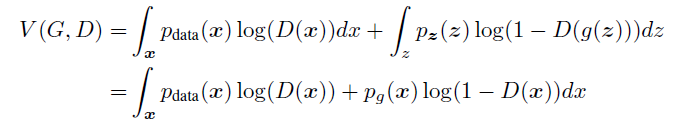
와 같이 표현되고, y → alog(y) + blog(1-y)일때 maximum은 $\frac{a}{a+b}$일 때 이다.
따라서 가정한 D*g(x)가 옳다.
- Theorem 1. The global minimum of the virtual training criterion C(G) is achieved if and only if pg = pdata. At that point, C(G) achieves the value - log 4.
- 다음과 같이 증명할 수 있다.

Convergence of Algorithm 1
- Proposition 2. If G and D have enough capacity, and at each step of Algorithm 1, the discriminator is allowed to reach its optimum given G, and pg is updated so as to improve the criterion, then pg converges to pdata
- proof

Experiments

- Parzen window-based log-likelihood estimates가 다른 모델들에 비해 더 좋은 결과를 가졌다.

- MNIST, CIFAR-10 등 다양한 데이터셋에 대해 학습을 진행하고, 생성을 진행해보았을 때 괜찮은 결과를 보였다.
Advantages and disadvantages
- 단점
- explicit한 분포 $p_g(x)$를 얻어낼 수 없고, D와 G가 학습 과정동안 잘 synchronized 되어야만 한다.
- 장점
- Markov chain이 필요하지 않고 단지 역전파만을 이용해 gradient를 얻어낼 수 있으며, 학습 과정동안 inference가 필요하지 않다.
- sharp 한 분포를 잘 표현할 수 있다.
- generator가 data로부터 직접 복사되며 update되지 않아 다양성이 증진된다.
Conclusions
- GAN은 이미지의 분포를 학습하는 generator 모델의 학습을 위해 이미지의 진위 여부를 파악하는 discriminator 모델을 만들어 둘 사이의 minimax game 형태로 alternative한 학습을 진행하였다.





댓글 영역