고정 헤더 영역
상세 컨텐츠
본문 제목
[7주차 / 박민규 / 논문리뷰] Big Transfer : General Visual Representation Learning
본문
Big Transfer
Transfer learning을 목적으로 만들어진 모델로 이전까지의 SOTA 보다 더 좋은 성능을 보이는 모델이다.
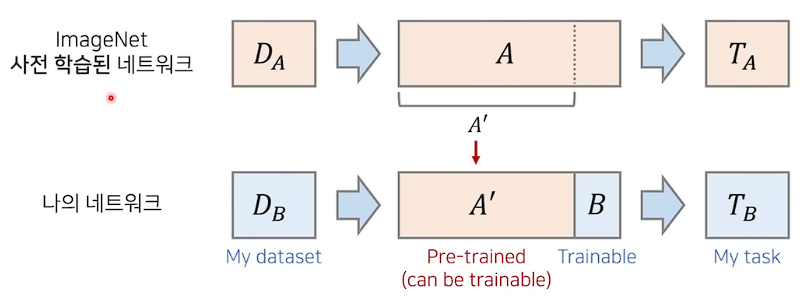
큰 크기의 dataset $D_A$로 pre-trained CNN을 불러와 feature extractor의 가중치를 BiT의 초기 가중치로 사용한다.
이때 pre-trained 네트워크를 학습시킨 $D_A$ 와 나의 네트워크를 학습시킨 작은 크기 dataset $D_B$ 가 유사한 특징을 가진다면, 사전학습된 네트워크의 Task $T_A$와 나의 네트워크의 Task $T_B$ 가 다르더라도 학습 속도 및 정확성의 향상이 이루어진다.
$T_A$와 $T_B$가 다르기 때문에 나의 네트워크의 초기 가중치를 사전 학습된 네트워크의 가중치($A'$)를 사용하고, 추가적으로 Dense layer를 붙여줘서 output size를 맞춰준다.
사전 학습된 네트워크에서 representation learning이 수행된 상태이기 때문에 $D_B$ 데이터셋에 대해서 feature 정보를 잘 추출할 수 있기 때문에 초기 가중치로 사용 가능하다.
나의 네트워크를 학습하기 위한 $D_B$ 데이터셋이 작다고 하더라도, 얻어진 representation을 토대로 추가적으로 학습하고자하는 가중치 B 조금만 붙여줘도 나의 네트워크는 금방 수렴할 가능성이 높다.
⇒ 따라서 작은 데이터셋 및 적은 epoch만으로도 높은 정확도를 보인다.
여기서 나의 네트워크는 downstream task라고도 하는데, pre-trained 모델을 이용해 실제로 풀고자 하는 문제를 의미한다.
Upstream pre-training
Scale
Upstream task는 prior task에 해당하며, 사전에 좋은 feature extractor를 만들기 위한 목적으로 학습한다.
BiT는 성공적인 사전학습pre-trained을 위해 데이터셋 및 네트워크의 스케일을 증가시킨다.
큰 크기의 데이터셋으로 단 한번의 pre-training을 수행하여 큰 스케일의 네트워크를 학습시킨다. 이후에 진행되는 downstream task로의 fine-tuning은 상대적으로 매우 낮은 비용이 요구되므로 효율적이다.
데이터셋은 다음과 같다.
- BiT-S : 약 130만 개의 이미지를 포함하는 ILSVRC-2012 데이터셋
- BiT-M : 약 1,400만 개의 이미지를 포함하는 ImageNet-21k 데이터셋
- BiT-L : 약 3억 개의 이미지를 포함하는 JFT-300M 데이터셋
네트워크는 ResNet에 기반한 구조를 가지고 있으며 다음이 나타낸다.
- ResNet-152x4는 152개의 Layer를 사용하며 width가 4배 증가된 Wide ResNet을 의미한다.
- ResNet-50x1 부터 ResNet-152x4 까지 다양한 scale(크기)의 아키텍처를 사용하여 실험을 진행한다.
Normalization
본 논문에서는 Batch normalization을 사용하지 않았다.
Model size가 크기때문에 데이터셋의 해상도 또한 크게 된다. 따라서 GPU 디바이스 당 작은 batch size를 사용하게 되는데, 이로 인해 batch가 너무 많아진다.
모든 장치에 대해 Statistics(평균,분산)를 수합하는 경우 동기화 비용이 많이 들고 성능이 하락하는 문제를 BN이 보인다. 따라서 batch size가 작아도 성능이 bounded되지 않는 Group Normalization와 weight standardization을 함께 사용하여 성능을 높힌다.
Batch Norm은 각 이미지마다 개별적으로, 일부 채널들을 묶어서 정규화하는 방법으로 Layer Norm과 Instance Norm의 장점만 취합한 것이다.
Downstream fine-tuning
Transfer learning
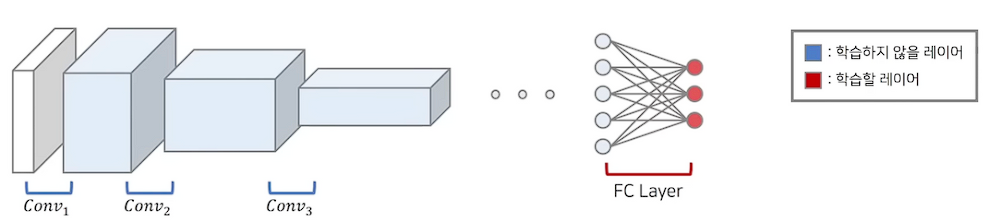
1. Freezing
앞부분 layer는 freezing해서 학습하지 않고, 마지막 layer만을 학습한다.
앞부분 layer는 건들지 않기 때문에 작은 크기의 데이터셋 $D_B$ 에 완전히 fitting 되도록 학습을 진행하지 않는다. 따라서 overfitting 문제에서 좋은 효과를 낼 수 있다.
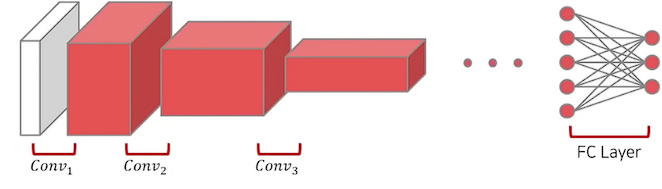
2. fine-tuning
앞부분 layer 또한 추가적으로 학습하고, 마지막 layer도 학습한다. 즉 모든 레이어를 학습한다.
기존 가중치도 이미 좋은 feature extractor로써 역할을 하지만, 추가적으로 $D_B$에 더 잘 fitting되도록 미세조정을 한다. 따라서 보다 더 좋은 정확도를 보인다.
학습
- BiT에서는 사전학습과 미세조정 과정에서 차이점이 존재하게 된다.
- Weight decay : 가중치에 대해 L2 norm(제약조건)을 걸어둬 정규화를 적용하는 것
- MixUp : 두 개 data씩 pair로 묶어서 학습을 진행하는 것으로 일종의 data augmentation 기법
사전학습은 weight decay를 사용하여 학습을 진행하고, 데이터가 풍부하므로 MixUp은 사용하지 않는다. 반면 미세조정은 weight decay 없이 학습을 진행하고, 데이터셋의 크기가 작으므로 MixUp을 사용한다.
- 그밖
Fine-tuning을 진행할 때 learning rate가 너무 크면 feature extractor에서 학습한 가중치가 많은 부분 변경될 수 있기 때문에, pre-trained 보다 상대적으로 적은 learning rate을 적용한다.
그리고 task의 난이도(category 개수)에 따라서 epoch수를 다르게 가져간다. → small, medium, large
Experiment

Generalist SOTA : Downstream task가 무엇인가에 구애받지 않은 general한 목적으로 만들어진 모델
Spcialist SOTA : 특정 downstream task에 대해서 가장 좋은 성능을 내는 것을 목표로 만들어진 모델
BiT-L : (JFT-300M 데이터셋) 3억개의 dataset으로 upstream task(사전학습) 진행 후, (ILSVRC-2012 데이터셋 기준) 100만개 dataset으로 downstream task(미세조정) 진행하여 만들어진 모델
ILSVRC-2012 BiT-L의 정확도는 87%로 100만개의 dataset으로 학습한 기존 Generalist SOTA(86%)보다 뛰어나다. 뿐만 아니라 Generalist 방식은 한 번의 large-scale training을 필요로 한다.
Specialist SOTA(88%)의 방식이 더 우수한 representation을 활용하여 더 높은 정확도를 보여주지만, task마다 큰 학습 비용이 요구된다.
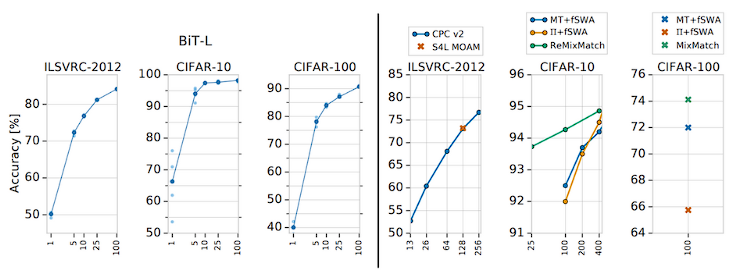
CIFAR-10에서 클래스당 1장의 이미지만 주어진 상황에서도 66%의 정확도를 보이며, 5장이 주어지면 94%의 정확도를 보인다.
즉, Class 당 image가 5개 있는 경우부터 수렴에 가까워지므로(높은 정확도 보임) Class당 image 몇개씩만 수집하면 되기에 레이블링하는 것이 비용이 큰 데이터셋의 경우 효과적으로 사용할 수 있다.
Few-shot learning 즉 class 당 image 개수가 적은 상황에서도 높은 정확도를 보인다.
당시 Semi-Supervised Learning SOTA인 ReMixMatch는 학습 data 5만장 중 250장만 labeled(10개의 class, class당 25장)되어 있고, 나머지 49,750장은 unlabeled된 경우이다. 해당 경우 약 94%의 정확도를 보인다.
class당 25장인 데이터셋으로 BiT를 fine-tuning할시에도 약 94% 정확도를 보이는데, downstream task에서는 효율적으로 fine-tuning 가능하기에 학습 시간이 ReMixMatch에 비에 훨씬 빠르다.
하지만 상황자체가 다르기에 직접적인 비교는 어렵다.
SSL은 학습분포 따르는 unlabeled data를 함께 활용하지만, transfer learning은 pre-training할 때 사용하는 ImageNet-21k에 class는 fine-tuning할 때 사용하는 CIFAT-10의 class에 포함되지 않을 수 있다. 즉, 분포 벗어나는 데이터셋을 이용해서 학습할 수 있는데 이로인해 transfer learning은 OOD labeled data를 활용하게 된다.

기본적으로 모델 architecture와 데이터셋이 클수록 높은 정확도를 보인다. 하지만, 네트워크 모델의 크기가 작을 때는 데이터의 크기가 커지면 오히려 정확도가 감소하는 문제가 발생할 수 있다.
무작정 데이터셋을 많이 늘린다고 해서 항상 좋은 결과를 보장할 수 없고, few-shot task에서도 마찬가지이다.
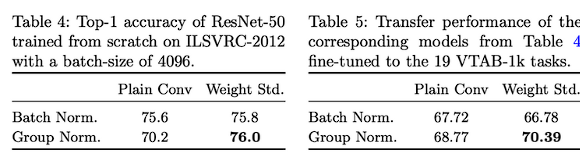
단순히 GN만을 사용할 때는 70.2로 정확도가 낮지만, WS를 함께 사용할 때 더 높은 정확도를 보이게 된다.
GN는 batch size에 의해 성능 bound가 발생하지 않기 때문에 batch size를 작게해 최대한 병렬로 학습을 진행한다면 학습 속도가 향상된다는 장점을 추가적으로 지니고 있다.





댓글 영역