고정 헤더 영역
상세 컨텐츠
본문 제목
[6주차/김희준/논문리뷰]Single-Shot Refinement Neural Network for Object Detection(RefineDet)
본문
논문 제목: Single-Shot Refinement Neural Network for Object Detection(RefineDet)
작성자: 17기 김희준
1. Introduction
object detection은 two-stage 방식과 one-stage 방식으로 나뉘어진다. two-stage 방식에는 Selective Search, RPN, R-CNN 등이 있고, one-stage 방식에는 YOLO, SSD 등이 있다.
one-stage 방식은 많은 연산량에도 불구하고 속도적인 측면에서 효율적이지만, class가 불균형하다는 문제로 인해 detection accuracy가 two-stage보다 뒤처져있다. two-stage는 비교적 느린 속도이지만, stage를 2개 거치는 만큼 훨씬 높은 detection accuracy를 보여주고 있다.
따라서 본 논문은 one-stage detector이면서 two-stage의 장점까지도 살린 RefineDet 프레임워크를 새롭게 제안한다.

아키텍처는 위 사진처럼 두 개의 모듈이 긴밀하게 연결된 형태이다. 상단에 있는 것이 ARM(Anchor Refinement Module), 하단에 있는 것이 ODM(Object Detection Module)이다. 마치 이 두 과정이 two-stage를 모방(imitate)하는 것처럼 보이는데, 이로써 two-stage 방식의 장점을 취할 수 있다고 한다.
ARM은 말 그대로 backbone에서 생성된 Anchor box를 정제(refine)해주는 역할을 맡는다. 생성된 anchor box 중 불필요한 box들은 제거하고 anchor box의 위치와 크기를 조정해준다. 이렇게 만들어진 refined anchors는 ODM으로 전달된다.
ODM은 refined anchors를 input으로 받아 object의 위치와 class를 예측하는 역할을 맡는다. 추가로 이 두 모듈을 이어주는 부분에 TCB(transfer connection block)가 존재하는데, 이는 ARM에서 만든 feature map을 ODM으로 전달해주는 역할을 한다.
2. Network Architecture
RefineDet는 feed-forward convolutional network로서, 고정된 개수의 bounding box와 box에 잡힌 object의 class에 대한 score를 출력한다.

대략적인 architecture는 위 그림과 같다.
Backbone은 보조적인 layer를 추가한 pre-trained VGG-16으로 구성된다(ImageNet 데이터로 pretrain). Backbone에서 만든 feature map은 ARM으로 전달된다. ARM에서 만들어진 feature map은 TCB로 전달되고 TCB에서 ODM으로 전달된 후 prediction layer가 class에 대한 score와 위치를 예측한다.
다음 3가지 파트는 RefineDet의 코어라고 할 수 있는 것들이다.
2.1. Transfer Connection Block(TCB)
앞서도 언급했듯이 TCB는 ARM과 ODM을 연결해주는 부분이다. ARM에서 만들어진 feature map을 ODM에 적합한 형태로 변형하여 전달한다. 이 때 ARM에서는 anchor의 위치에 관한 feature와 class에 관한 feature가 만들어지는데, TCB에서는 오직 anchor의 위치에 관한 feature map만을 전달받는다.

figure2는 TCB를 도식화한 것이다.
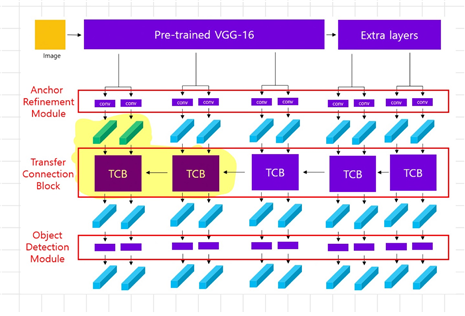
위 사진은 전체 아키텍처에서 TCB 부분을 형광펜으로 칠한 것이다. 이 때 TCB에 input으로 들어오는 것은 두 가지이다.
- refined anchor: ARM을 거쳐 정제된 anchor이다. conv layer를 통과시켜 256 채널 크기로 변형된다.
- high-level feature: 한 층 더 깊은 layer에서 만든 feature이다. 이는 이미 앞서 ARM과 TCB를 통해 만들어진 feature이다. 이는 deconvolution 연산으로 크기를 키워준다.
이 두가지 feature를 element-wise sum으로 합해준다. 더 깊은 layer에서 추출한 정보도 추가되므로 더 많은 정보를 효과적으로 담을 수 있다.
2.2. Two-step Cascaded Regression
기존의 one-stage(one-step) 방식은 작은 크기의 object에 있어서 낮은 정확도를 보여왔다. 그래서 본 논문은 two-stage(two-step) 방식을 도입했고, 이 방식은 계속 언급해온 ARM~ODM으로 이어지는 방식을 뜻한다.
우선 ARM에서 균등하게 나눠진 feature map의 cell에 n개의 anchor box를 할당하고, 초기 위치값을 설정한다. 훈련을 거쳐 잘 정제된(refined) anchor들은 object를 포함하고 있을 confidence score와 위치값을 TCB로 보낸다.
2.3. Negative Anchor Filtering
불균형한 문제를 완화하기 위해 negative anchor를 없애야 한다. 이 때 negative anchor란 object가 포함되지 않은 anchor box인데, 대체로 object가 포함되지 않은 경우가 훨씬 많기에 sample이 불균형해지는 문제가 생긴다. 이를 해결하기 위해 negative filtering mechanism을 사용하여 너무나 확연한 negative anchor를 제거한다. 훈련 중 만약 negative confidence score가 특정 임곗값(주로 0.99)보다 높다면 그 anchor를 제거하는 방식이다.
3. Training and Inference
1) Data Augmentation
본 논문은 SSD 논문에서 사용한 것처럼 랜덤하게 train 이미지를 왜곡하고 뒤집고 늘리는 등 augmentation을 수행한다.
2) Backbone Network
Backbone으로는 pretrain된 VGG-16과 ResNet-101을 사용한다. 이 때 VGG-16의 fc6, fc7 layer를 conv_fc6, conv_7 layer로 수정한다. 또한 conv4_3, conv5_3 layer가 다른 layer들과 크기가 다르기 때문에 L2 normalization을 진행해준다. 또한 high-level feature에 대한 정보를 얻기 위해 가장 마지막 단에 conv6_1, conv6_2 layer를 추가해준다.
3) Anchors Design and Matching
다양한 크기의 object를 잘 포착해내기 위해서 layer의 stride 크기를 8, 16, 32, 64로 다양하게 설정해본다. 각기 다른 크기의 layer들을 각각 다른 scale을 가진 anchor와 매칭시킨다.
4) Hard Negative Mining
대부분의 anchor box는 negative(object가 포함되지 않음)하다. 따라서 이 불균형을 해소하기 위해 negative로 분류되기 쉬운 anchor box들을 삭제한 후 negative sample이 positive sample의 3배가 넘지 않도록 조정한다.
5) Loss function
loss function은 loss in the ARM과 loss in the ODM으로 나뉜다.
우선 ARM에서는 anchor box 안에 object 유무를 binary 형태로 계산하고, 위치와 크기를 regression한다. 그리고 ODM에서는 object의 종류를 multi class로 계산하고, ARM과 마찬가지로 위치와 크기를 regression한다.
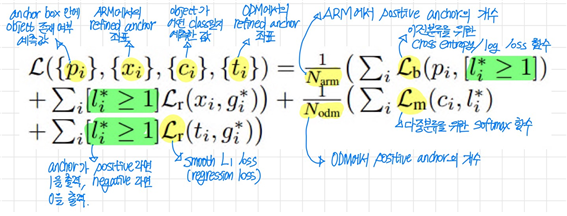
이중분류일 때는 cross entropy, 다중분류일 때는 softmax를 loss 함수로 사용하고, 좌표값을 계산하는 regression에선 smooth L1을 loss 함수로 사용하는 것을 볼 수 있다.
5. Experiments

table1에서 알 수 있듯이 RefineDet는 비교적 적은 anchor box를 가지고도 가장 좋은 성능을 보여주고 있다.
본 논문이 골자로 한 1)Negative anchor filtering이 없을 경우 mAP가 0.5% 하락했고, 2)Two-step cascaded regression이 없을 경우 mAP는 2.2%가 하락했으며, 3)TCB가 없을 경우 mAP는 1.1% 하락했다.
'2023 Summer Session > CV Team 1' 카테고리의 다른 글
| [7주차/강민채/논문리뷰] CornerNet (0) | 2023.08.14 |
|---|---|
| [6주차/강민채/논문리뷰] M2Det (0) | 2023.08.09 |
| [6주차/논문리뷰/이서연] Faster R-CNN (1) | 2023.08.07 |
| [4주차/김희준/논문리뷰]Generative Adversarial Nets (1) | 2023.08.05 |
| [5주차/강민채/논문 리뷰] YOLOv7 (0) | 2023.08.04 |





댓글 영역