고정 헤더 영역
상세 컨텐츠
본문 제목
[5주차/최유민/논문리뷰] Diffusion Models : A Comprehensive Survey of Methods and Applications / Text-to-image model
본문
이 글에선 최근 많이 이용되고 있는 Stable Diffusion, controlNet에 이용되는 Diffusion 모델이 어떻게 발전해 왔는지에 대해 알아보고자 한다.
각 모델에 대해 깊게 이해하기보다 최대한 많은 모델을 살펴보면서 앞으로의 공부 방향에 대해 고민해보았다.
Diffusion Models: A Comprehensive Survey of Methods and Applications
Diffusion models have emerged as a powerful new family of deep generative models with record-breaking performance in many applications, including image synthesis, video generation, and molecule design. In this survey, we provide an overview of the rapidly
arxiv.org
1. Diffusion Model

디퓨전 모델이란?
데이터에 노이즈를 주입하는 forward process와,
이와 반대로 노이즈를 조금씩 복원해나가면서 이미지를 생성해내는 reverse process를 활용하는 모델
reverse process를 학습하여 노이즈로부터 데이터를 복원해 나가면서 데이터를 생성해 낸다.
1.1 Denoising Diffusion Probabilistic Models (DDPMs)
기존 모델에서 Loss term을 발전시킨 모델
loss term과 parameter estimation 과정을 더 학습이 잘 되는 방향으로 발전시킨 논문.
조금의 성능 향상이 있었고, 많은 diffusion 연구의 기반이 된다.
1.2 Score-Based Generative Models (SGMs)
Score function : 주어진 pdf p(x) 에 대해서 score function 은 gradient of the log probability density ∇x log 𝑝(x)

Score를 이용해서 노이즈로부터 데이터로 업데이트될 때 원하는 이미지(data 밀도가 높은 곳의 이미지)를 얻도록 만든다.

1.3 Stochastic Differential Equations (Score SDEs)
SDE에서는 noise scale을 무한하다고 본다.
즉, t를 연속적인 시간 변수로 표현하는 것

2 Multi-Modal Generation
다음으로, 위 Diffusion 모델이 Multi Modal Generation 에 어떻게 이용되는지를 살펴보려고 한다.
2.1 Text-to-Image Generation
Diffusion 을 이용한 대표적인 Multi Modal Generation의 예시로는 Text-to-Image generation이 있다.
DALLE2 : 2 stage model
DALLE2 는 text-to-image 를 위해 2stage model 을 제안하였다. CLIP + DDPM 이다.
- CLIP
OpenAI에서 발표한 모델. image-text의 joint representation space를 학습한다.
CLIP 논문은 기존 ImageNet 보다 방대한 (4억개) 용량의 이미지 데이터를 사용하여 representational learning을 수행하였다.
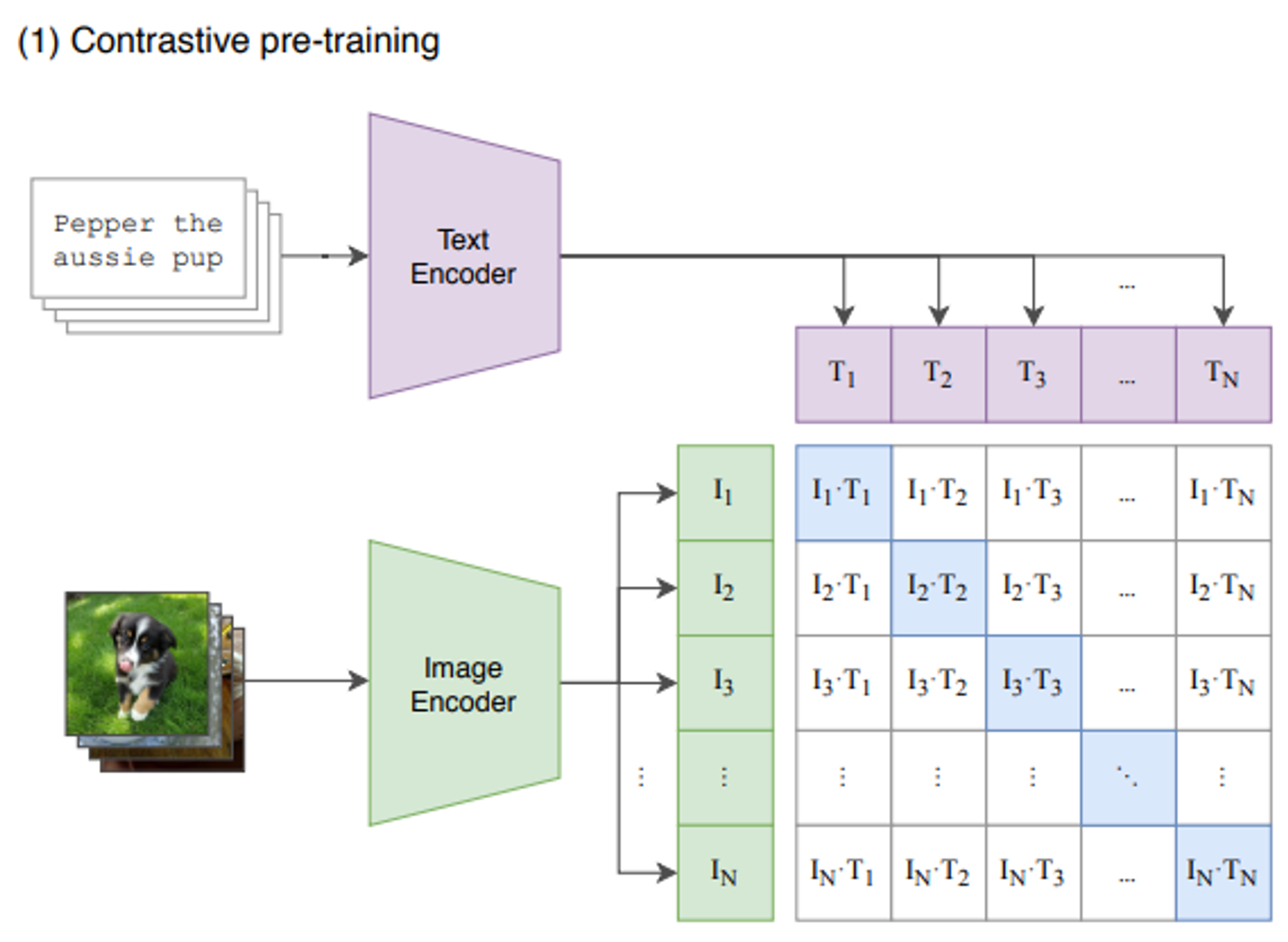
- image와 text를 하나의 공통된 space로 보낸 다음
- positive pair에서의 유사도(cosine similarity)는 최대화하고
- negative pair에서의 유사도는 최소화하도록
- CE loss를 사용하여 학습한다.
- DDPM

점선 위쪽은 CLIP모델의 학습을 나타내고, 점선 아래쪽은 Text-to-image generation process를 나타낸다.
- A prior P(z_i |y) that produces CLIP image embeddings zi conditioned on captions y
- A decoder P(x|z_i , y) that produces images x conditioned on CLIP image embeddings zi (and optionally text captions y).
위 CLIP 모델을 텍스트 인코딩 과정에서 이용하여 z_i 벡터를 나타낼 수 있다.
z_i벡터에 diffusion model(DDPM)을 디코더로 이용하면, Text-to-image task를 달성할 수 있다.
prior model 에 대해 논문에서는 두 가지 방법을 제시하고 있다.
- Autoregressive (AR) prior
- Diffusion prior
Stable Diffusion
다음은 또 다른 text-to-image의 대표 모델 stable diffusion이다.

위 그림이 전체 모델이다. 쉬운 이해와 Diffusion 모델 사용에 집중하기 위해, 모델을 간소화해서 설명하고자 한다.
1단계 : Stable Diffusion은 잠재 공간(latent space)에 무작위 텐서(random tensor)를 생성

2단계 : 노이즈 예측기(U-Net)가 잠재 노이즈 이미지와 텍스트 프롬프트를 입력받아 노이즈를 예측

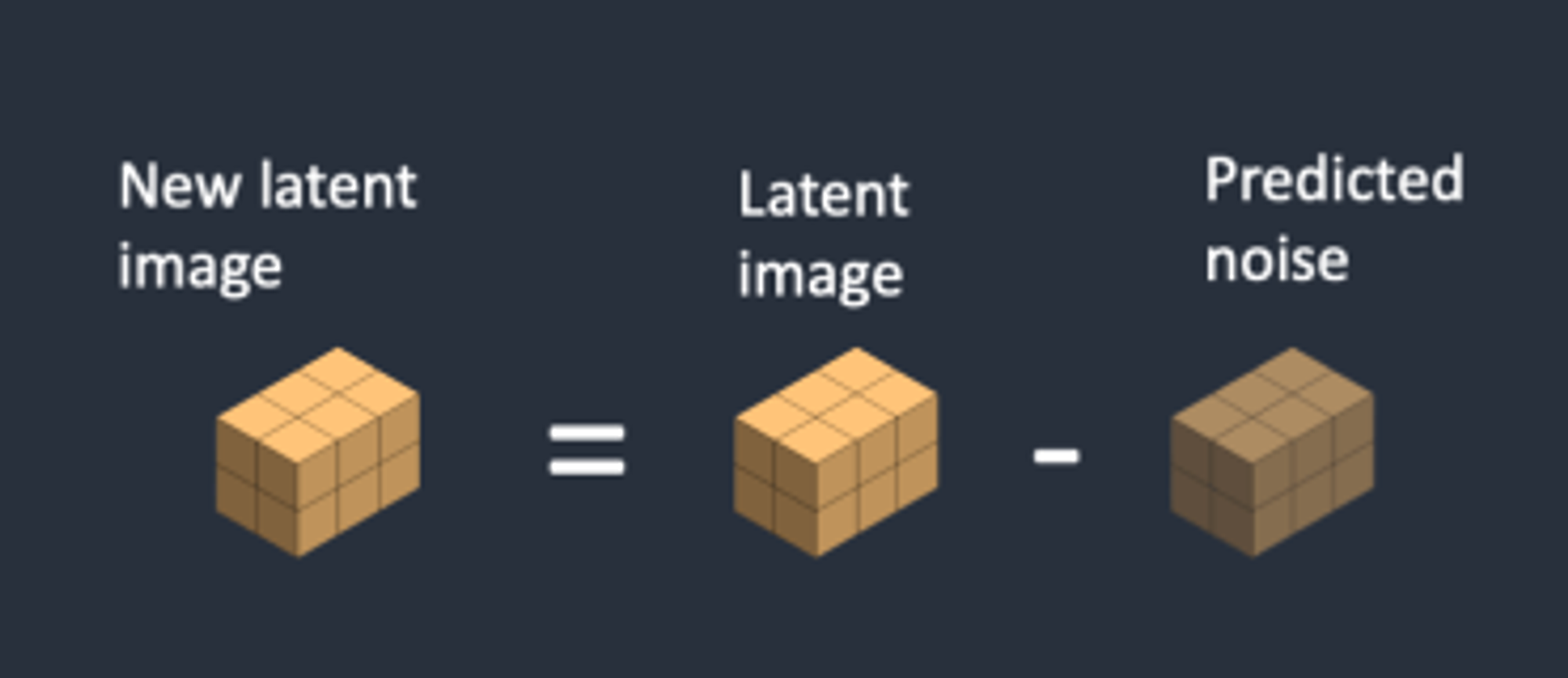
3단계 : 잠재 이미지에서 잠재 노이즈를 제거(Diffusion 사용)
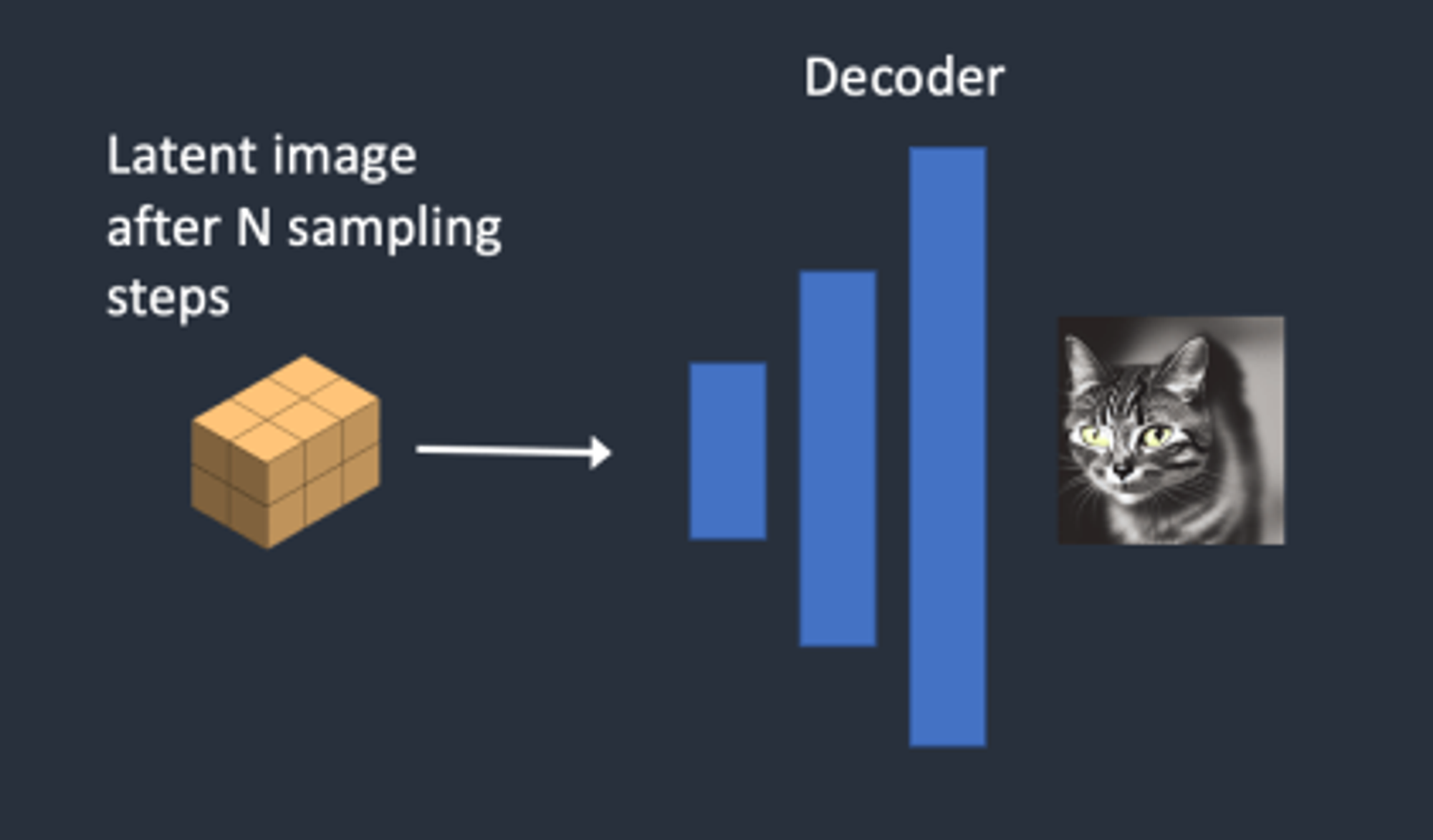
4단계 : 최종적으로 VAE 디코더가 잠재 이미지를 픽셀 공간으로 보내어 이미지를 생성
ControlNet
위 모델들의 단점은 사용자가 원하는 특정 condition을 생성하기 어렵다는 데 있다. 특
특정 object shape나 pose 를 가지고 있는 이미지를 생성하려면 그 데이터가 필요한데, 하나에 포즈에 대해서만 데이터셋을 대량으로 구축하기 어렵기 때문이다.
위의 문제 상황에서 제시된 모델이 ControlNet이다.
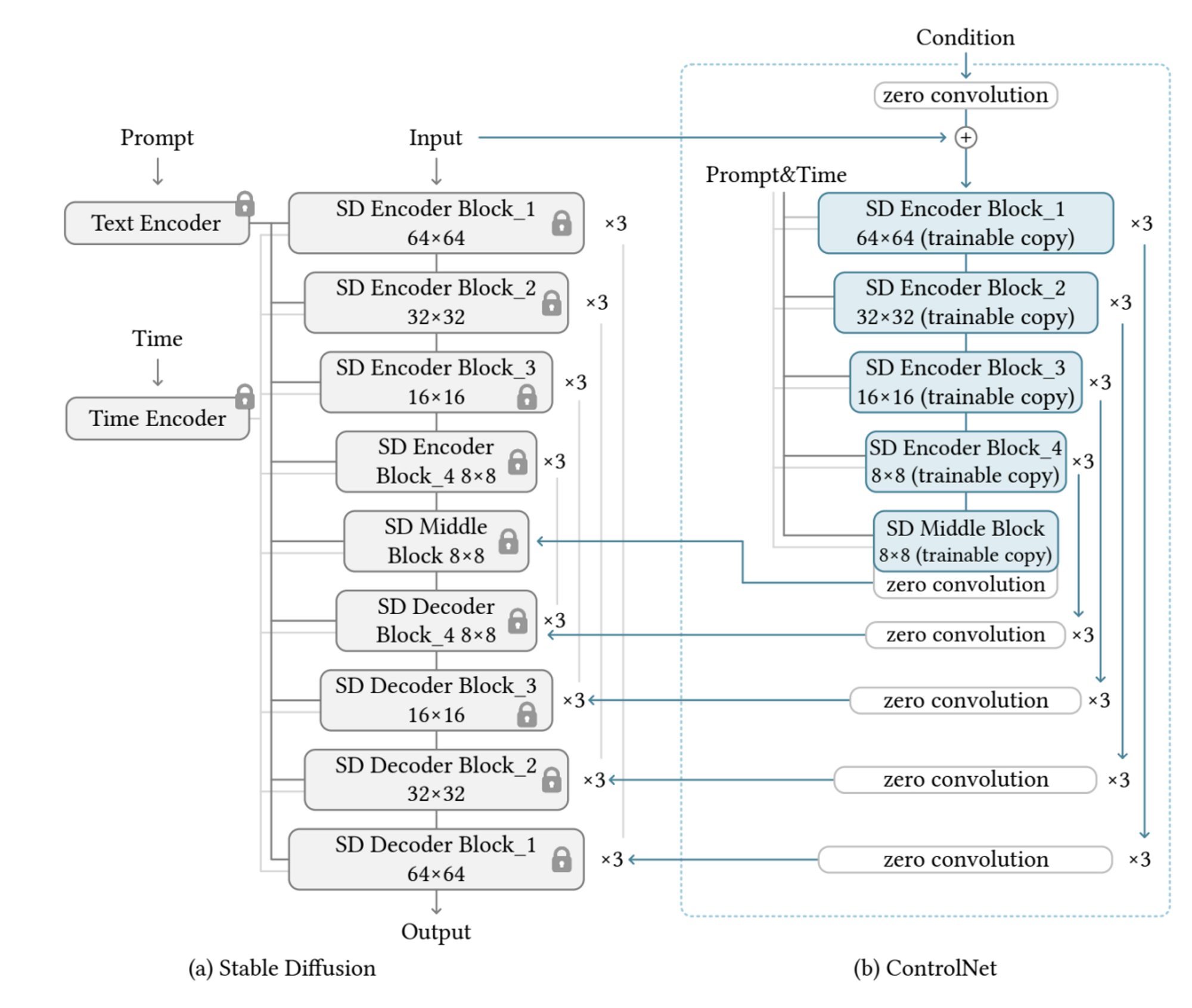
위 모델은 학습 불가능한 원래의 Stable diffusion모델(a) 과 학습 가능한 병렬로 구성된 모델(b)로 이루어져 있다.
회색 블록들은 그대로 유지되면서 고품질의 이미지를 생성하는데 문제가 되지 않도록 한다.
* ControlNet에서는 zero convolution이 사용되고 있다.
Zero convolution은 모두 zero로 초기화 된 convolution filter를 말하며 이는 training이 시작되는 당시에는 ControlNet 구조에 의한 input/output 관계가 사전 학습된 diffusion의 input/output과 전혀 차이가 없다는 것이고, 이로 인해 optimization이 진행되기 전까지는 neural network 깊이가 증가함에 따라 영향을 끼치지 않는다는 것을 알 수 있다.
ControlNet의 zero convolution에 대한 자세한 내용은 해당 모델을 공부할 때 알아보기로 하자.

ControlNet을 이용한 결과물이다. Candy Edge를 따라서 이미지가 생성되었음을 볼 수 있다.
본 Survey 논문에서는 위 text-to-image task 이외에도 아래 task에 대해 Diffusion 이 사용되고 있고, 대표적인 모델들에 대해서 언급하고 있다.
Scene Graph-to-Image Generation
Text-to-3D Generation.
Text-to-Motion Generation
Text-to-Video Generation
Text-to-Audio Generation
참고자료
1. Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems
2. Score-Based Generative Modeling through Stochastic Differential Equations, ICLR 2021 (Oral)
3. Hierarchical Text-Conditional Image Generation with CLIP Latents
4. High-Resolution Image Synthesis with Latent Diffusion Models
5. Adding conditional control to text-to-image diffusion models
Score-based Generative Modeling by Diffusion Process
[논문 리뷰] DALL-E 2 : Hierarchical Text-Conditional Image Generation with CLIP Latents
'2023 Summer Session > CV Team 3' 카테고리의 다른 글
| [4주차 / 최유민/ 논문 리뷰] VAE(Variational autoencoder) (0) | 2023.08.06 |
|---|---|
| [4주차/CV3팀/논문리뷰]Generative Adversarial Nets (0) | 2023.08.06 |
| [5주차/장수혁/논문리뷰] Diffusion Models in Vision: A Survey (0) | 2023.08.03 |
| [5주차/임청수/논문리뷰] Denoising Diffusion Probabilistic Model (0) | 2023.08.03 |
| [3주차/임청수/논문리뷰] Image Style Transfer Using Convolutional Neural Networks (0) | 2023.07.26 |





댓글 영역