고정 헤더 영역
상세 컨텐츠
본문
논문 제목: YOLO9000:Better, Faster, Stronger(YOLOv2)
작성자: 17기 김희준
1. Introduction
현재 object detection의 데이터셋은 classfication과 같은 여타 task에 쓰이는 데이터셋보다 양이 현저히 적다. 본 논문은 YOLO9000을 소개하며 classification에서 쓰이는 많은 양의 데이터셋(ImageNet)과 비교적 적은 양의 detection 데이터셋(COCO)을 함께 학습하는 방식을 사용한다. 이름에 붙은 9000은 9000개의 object를 detect할 수 있다는 의미이다.
논문에서는 3가지 파트로 나누어 모델을 설명하고 있다.
- Better: YOLOv1의 단점과 이를 개선한 내용
- Faster: YOLOv2의 neural net인 Darknet-19
- Stronger: YOLO9000 소개
2. Better
YOLOv1의 단점은 아래 두 가지로 요약할 수 있다.
- localization error가 많다는 점이다. localization error란 bounding box의 location을 제대로 포착하지 못하는 오류를 말한다.
- region proposal을 기반으로 한 모델에 비해 recall이 낮다는 점이다. recall은 실제 object 중 제대로 box를 predict한 것들의 비율을 의미한다.
일반적으로 더 좋은 성능을 얻기 위해선 neural net의 크기를 키우는 방식이 일반적이다. 그러나 본 논문은 오히려 경량화를 함으로써 성능 향상을 꾀한다.
- Batch Normalization: 다른 형태의 regularization을 모두 없애고 모든 convolutional layer에 batch normalization을 추가하였다. 이로써 dropout 없이도 overfitting을 피할 수 있었고, 2% mAP 성능향상도 이뤄냈다.
- High Resolution Classifier: YOLOv1 모델은 256*256 input을 사용하여 train을 하는 반면 detection에 쓰이는 크기는 448*448여서 호환이 되지 않았다. 이를 개선하기 위해 YOLOv2는 448*448 input으로 train을 시켰다. 즉, input을 보다 고해상도(high resolution)로 바꾸어주었다. 이를 통해 4% mAP 성능 향상을 보였다.
- Convolutional with Anchor Boxes: YOLOv1 모델은 fully connected layer를 사용하여 bounding box의 좌표를 direct하게 예측했다. 그러나 YOLOv2는 fully connected layer를 제거하고 anchor box를 사용하여 bounding box를 예측한다.
구체적인 방식은 다음과 같다. pooling layer를 제거함으로써 output의 해상도를 높인다. 이 때 448*448로 만드는 것이 아니라 416*416으로 만든다. 416을 down sampling하면 13*13의 feature map이 만들어지는데, 홀수*홀수의 feature map이 만들어지면 grid cell 역시도 홀수가 되어 가장 중앙에 있는 grid cell을 하나로 고를 수 있다. 하나의 중앙 cell이 있는 경우 큰 크기의 object를 잘 포착할 수 있는 이점이 있다. 만약 짝수*짝수였다면 이 같은 접근이 불가능하다.
YOLOv1은 각 grid cell별로 2개의 bounding box를 예측하는 반면, v2는 anchor boxes를 사용하여 훨씬 많은 수의 bounding box를 예측한다. 이 경우 mAP는 살짝 하락하지만, recall 값이 높아진다.
4) Dimension Clusters:
이전 모델들만 해도 anchor box의 scale과 aspect ratio를 사전에 미리 정의(hand-picked)했다. 이는 임의로 설정된 값이다. 만약 알고리즘을 통해 효율적으로 이 값을 설정한다면 모델의 성능 역시 높아질 것이다.
본 논문은 VOC, COCO 데이터셋의 ground truth box 좌표들을 k-means clustering하여 anchor box의 크기와 비율을 결정한다.

본 논문이 정한 최적의 cluster 개수는 k=5였다. 이 때 cluster 개수가 곧 anchor box의 개수인데, 이전 논문들이 9개의 anchor box로 낸 성능과 본 논문이 5개의 anchor box만으로 낸 성능이 거의 일치하다는 점에서 k-means clustering이 큰 효과를 본다는 것을 알 수 있다.

table1에서 보이듯, Cluster IOU 방식은 anchor box가 5개여도 기존 방식(60.9)보다 근소하게 높은 성능(61.0)을 보이고 있다.
5) Direct location prediction:

anchor box의 위치를 조정할 때는 위 수식을 바탕으로 중심점 x,y 좌표를 구한다. 그러나 이 때 t_x, t_y 값에는 별다른 범위 제한이 없기 때문에 iteration이 진행되다보면 중심점이 난데 없는 곳에 위치할 불안정성이 생긴다.
본 논문은 이 점을 해결하기 위해 grid cell을 기준으로 상대적인 위치 좌표를 예측하는 방법을 택했다. 이 방식은 YOLOv1 논문에서도 언급된 바 있다.
6) Fine-Grained Features:
앞서 언급했듯이, YOLOv2의 output 크기는 13*13이다. 이는 큰 object 예측에는 유리하지만, 작은 object 예측에는 불리하다. 이 점을 극복하기 위해 마지막 pooling을 수행하기 전에 26*26*512 크기의 feature map을 13*13*2048 크기로 변환한 후, 정상적으로 pooling을 거친 13*13*1024 feature map과 concat하여 13*13*3072 feature map을 얻는다. 그 결과 mAP가 1%가량 향상되었다.

YOLOv2 architecture를 보면, 마지막 pooling(빨간색) 이전에 feature map을 13*13*2048(노란색)으로 변환한 후 13*13*1024와 결합(초록색)하는 것을 볼 수 있다.
7) Multi-Scale Training:
YOLOv2는 fully connected layer 없이 conv layer와 pooling으로만 구성되어있다. 이러한 특징 덕분에 input 크기를 다양하게 바꿀 수가 있다. 학습 과정에서 10번의 batch동안 다양한 크기의 input을 시도해보았는데, downsample이 32 단위로 되기 때문에 {320, 352, ... , 608} 크기로 resize할 수 있었다.

그 결과 성능은 위 사진과 같았다. 544*544 input을 사용할 경우 mAP가 78.6으로 가장 높게 나왔고, fps(frame per second) 역시 뛰어난 편이다.
3. Faster
이전까지의 detection framework는 VGG-16이 대부분이었다. 물론 우수한 성능을 보이지만, 불필요하게 복잡하다는 단점이 있었다.
본 논문은 Darknet-19이라는 framework를 사용한다.

구조는 위와 같다. 19개의 conv layer와 5개의 max pooling layer로 구성되어있다. 특이한 점은 마지막에 fully connecte layer 없이 global average pooling을 한다는 점이다. 이로써 파라미터 수를 감소시키고 속도도 더욱 빨라졌다.
3. stronger
이제껏 살펴본 YOLOv2를 classification 데이터셋(ImageNet)와 detection 데이터셋(COCO)을 함께 사용하여 학습시킴으로써 9000개의 class를 예측하는 YOLO9000을 만들 수 있다. 만약 detection 데이터셋이 input으로 들어오면 YOLOv2 loss function 기반으로 backpropagation을 한다. 반면 classification 데이터셋이 input으로 들어오면 classification에 사용되는 parameter만 backpropagation을 진행한다.
다만 detection 데이터셋은 크기가 작은만큼 class의 개수도 많지 않다. classification 데이터셋에서 ‘Norfolk terrier’, ‘Yorkshire terrier’로 세분화되는 것과 달리 ‘dog’으로 보다 일반화된 레이블링이 되어있다.
이 문제를 해결하기 위해 Hierarchical한 특성을 가진 ImageNet의 레이블링을 활용한다. ImageNet 데이터셋은 ‘Norfolk terrier’, ‘Yorkshire terrier’가 같은 ‘terrier’라는 상위 속성을 가지고, ‘terrier’의 상위 속성은 ‘dog’이라는 구조를 담고 있다. 이를 활용하여 WordTree를 만들 수 있는데, Hierarchical한 덕분에 특정 object으로 분류할 때 조건부 확률을 이용할 수 있다. 만약 object가 Norfolk terrier일 확률을 구하려면 아래처럼 계산할 수 있다.

wordtree는 아래 사진처럼 구성된다. wordtree방식으로 COCO 데이터셋과 ImageNet 데이터셋을 결합하여 9418개 class를 가진 데이터셋을 만든다. 이 때 ImageNet 데이터셋의 크기가 더 크므로 COCO 데이터셋을 4배 oversampling한다. 앞서 anchor box를 5개 사용한다고 했지만, output 크기의 한계로 인해 3개만을 사용한다.
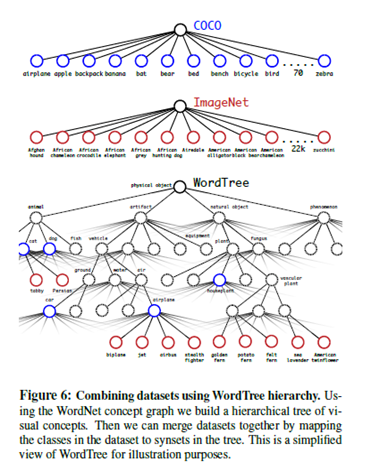
학습 시, 위에서 언급한 것과 같이 detection data의 경우 full loss를 역전파하고, classification data의 경우 classification loss 부분만 역전파 한다. 또한 classification에서 label의 하위 범주(node)들은 학습에 고려하지 않고, 상위 범주(node)들만 고려한다. 예를 들면, 범주가 "dog"인 경우 상위 범주인 "animal"은 고려해서 학습하지만 하위 범주인 "terrier"는 고려하지 않는다.
이러한 학습 방법을 통해 YOLO v2는 9000개 이상의 범주를 detection할 수 있는 YOLO9000이 된다. 이를 따서 논문의 제목이 "YOLO9000"이 되었다.
'2023 Summer Session > CV Team 1' 카테고리의 다른 글
| [5주차/강민채/논문 리뷰] YOLOv7 (0) | 2023.08.04 |
|---|---|
| [5주차/이서연/논문리뷰] YOLOv5 (0) | 2023.08.03 |
| [4주차/이서연/논문리뷰] Generative Adversarial Nets (0) | 2023.08.01 |
| [4주차/강민채/논문리뷰] Generative Adversarial Nets (0) | 2023.07.31 |
| [3주차/이서연/논문리뷰] Style Transfer (0) | 2023.07.26 |





댓글 영역