고정 헤더 영역
상세 컨텐츠
본문 제목
[2주차/전병우/논문리뷰] DETR: End-to-End Object Detection with Transformers
본문
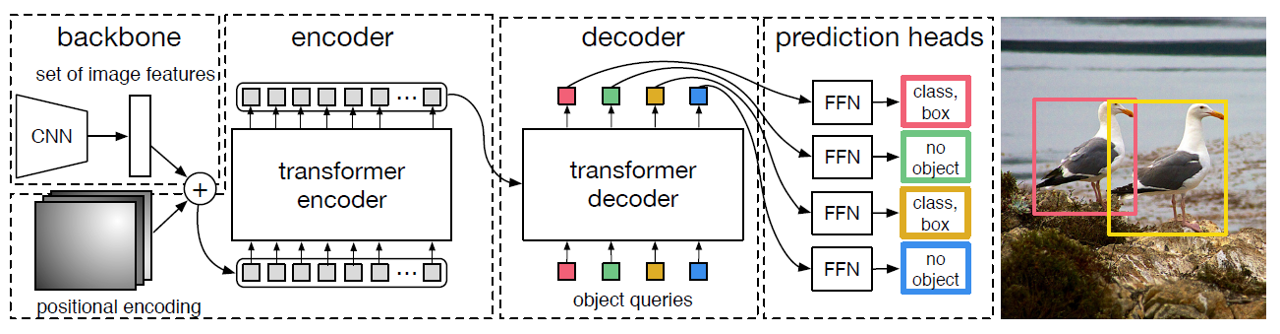
DETR은 ECCV2020에 publish된 논문으로, ViT와 더불어 transformer 철학을 Vision task에 최초로 적용한 논문이다. 본 논문을 이해하기 위해서는 Attention Is All You Need (A.Vaswani et al.)를 정확히 이해하는 것이 필요하겠지만, Vanilla Transformer의 경우 NLP task를 해결하기 위해 제안된 아키텍쳐임으로 해당 내용에 대한 공부는 독자에게 맡겨두겠다.
DETR의 main contribution은 global context-aware하게 object를 detect할 수 있는 end-to-end 모델이란 점이다.
다음으로 본 모델의 notable한 특징들을 몇 가지 살펴보자.
1. 무엇보다도 transformer의 철학을 가져간다는 점에서, inductive bias가 거의 없다.
inductive bias가 (거의) 없는 것은 general한 image distribution을 배우기에는 적합하지만 training set이 적으면 overfitting이 생길 수 있다는 문제도 있다. 데이터가 적으면 bias를 빠르게 학습하는 것이다. 예컨데 소는 풀 위에 자주 있다보니 풀만 봐도 소라고 shortcut을 배우는 셈이다. 그러다보니 Faster R-CNN보다 convergence가 느리다.
2. No anchor box, No regression of box transforms
DETR의 forwarding 과정을 정리한다면 다음과 같다.

- CNN을 통해서 image feature를 뽑아낸다.
- feature를 patch로 flatten 시킨 후, transformer encoder에 넣어서 embedding을 학습한다.
- encoder의 embedding을 key & value로 활용하여, object query를 decoder에 넣는다.
- decoder의 output을 FFN(Feed-Forward Network)을 통과시켜 각각에 대한 class와 box를 얻어낸다.
이러한 모델 아키텍쳐가 제안된 것은, 저자들이 object detection 문제를 set prediction problem으로 봤기 때문이다. 이를 바탕으로 CNN-based의 object detecion 모델들에 비해 training pipeline을 많이 diet할 수 있었다.
3. Bipartite matching (이분 매칭)
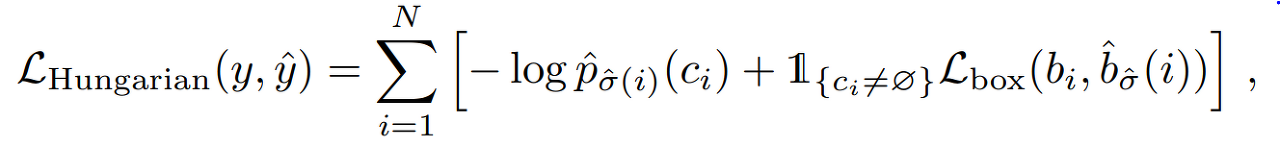
DETR는 predicted bounding box와 ground truth를 one-to-one으로 matching하는데 이 때 bruteforce에서 오는 complexity를 mitigate하기 위해서 Hungarian Loss를 사용한다. Hungarian Loss의 수식은 복잡하지만 결국 matching cost가 가장 낮은 순열이 output이 되도록 설계되어있는 loss function이다. 사실 헝가리안 알고리즘은 알고리즘 업계에서는 well-known이다.
이 loss를 흘려줌으로써 set이 ground-truth와 연결되면서 비로소 의미를 갖게 된다.
이후 segmentation model에 많은 영감을 주었기에 loss는 주목할 만하며, 또한 이를 통해 저자들은 NMS와 같은 R-CNN계열의 고질적인 computation cost를 한방에 날려버림으로써 training pipeline을 diet하였다.
Contribution & Limitaition
- Contribution
- Transformer 구조를 Object Detection에 활용한 첫 사례
- bipartite matching을 통한 object detection 해결
- Limitation
- Slow convergence (due to its inductive bias)
- Small object detection이 잘 안된다
- 현대의 detection model들은 high-resolution feature map으로부터 작은 객체들이 object들이 detect되지만, 무작정 feature map resolution을 높이면 transformer encoder의 self-attention가 큰 complexity를 갖게 된다.
- DETR은 resnet의 마지막 feature map을 사용하는데, 이 feature map은 high-level feature map을 가질지는 몰라도, 작고 정교한 feature는 부족하다. (후속 논문인 Deformable DETR에서는 FPN과 같은 구조를 사용하면 이를 해결할 수 있다고 주장한다)
추가적으로, DETR는 object detection 뿐만 아니라 segmentation task에도 큰 영향력을 끼쳤으며, 본 논문 이후로 segmentation task를 per-pixel classification이 아니라 mask classification으로 풀고자 하는 접근이 많아졌다. 본 논문의 panoptic segmentation으로의 응용은 다음과 같다.

또한 DETR for panoptic segmentation에 대해 개인적으로 공부했던 내용을 첨부해본다. 위 figure 4의 상세한 아키텍쳐이다.






댓글 영역